Две низкоуровневые оптимизации,
которые я сделал вчера
Или:
— как я сидел дома и писал код.
Оптимизации в ClickHouse
+ Скорость работы — основное свойство продукта ClickHouse.
+ Мы постоянно всё оптимизируем...
− Каждая оптимизация — это сложный эксперимент.
− Иногда эксперимент проваливается уже в продакшене.
Примеры спорных оптимизаций
 Оптимизации, которые люди старательно сделали,
Оптимизации, которые люди старательно сделали,
но которые потом «выстрелили» в обратную сторону.
Из ядра Linux:
— NUMA awareness;
— Huge Pages.
С точки зрения разработчиков:
— это хорошие оптимизации; во всех проблемах виноваты пользователи.
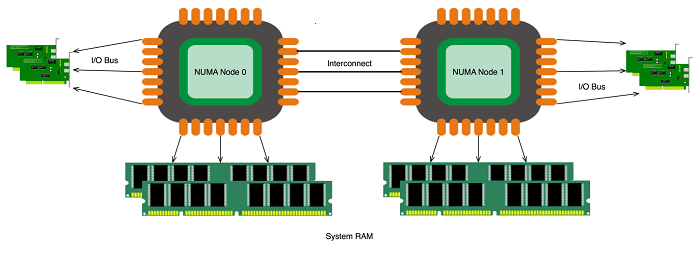
NUMA Awareness
— в системе несколько процессоров;
— скорость доступа к памяти неравномерна;
— части памяти относятся к разных процессорам;
— работа со «своей» памятью быстрее.
NUMA Awareness
Как выделять физическую память:
1. Как попало.
2. В той части памяти, которая относится к процессору,
который сейчас выполняет код.
Huge Pages
— программы работают с виртуальной памятью;
— виртуальная память отображается на физическую;
— с помощью таблицы трансляции адресов (page table);
— единица отображения — страница памяти;
— на x86_64 по-умолчанию размер страницы — 4 КБ;
— таблица трансляции адресов сама тоже хранится в памяти;
Huge Pages
Таблица трансляции адресов хранится в памяти;
— на x86_64 по-умолчанию размер страницы — 4 КБ.
Пример: программа использует 200 GiB оперативки;
— это до 50 млн. записей в таблице трансляции адресов.
Структура данных таблицы трансляции адресов
— 5-уровневый 512-way trie.
Чтобы прочитать что-то из виртуальной памяти,
надо ещё 5 раз прочитать что-то из памяти?
— кэшируется CPU с помощью TLB.

Bellezzasolo - Own work, CC BY-SA 4.0, Wikipedia, 2018
TLB, пример
AMD Zen 2
iTLB:
— 64 entry L1, fully associative;
— 512 entry L2, 8-way set associative.
dTLB:
— 64 entry L1, fully associative;
— 2048 entry L2, 16-way set associative.
Информация с сайта wikichip.org.
Huge Pages
Отображение адресов кэшируется с помощью TLB.
Размер TLB маленький.
Непопадание в TLB — чтение из памяти (надеемся из кэша).
Всё тормозит?
Решение — включить Huge Pages.
На x86_64 можно использовать страницы
размером 2 МБ или 1 ГБ вместо 4 КБ.
Huge Pages
— явно выделенные huge pages:
# echo 10 > /proc/sys/vm/nr_hugepages
также смотрите hugetlbfs.
— transparent huge pages:
$ cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
Примеры спорных оптимизаций
— NUMA awareness;
— Huge Pages.
С точки зрения разработчиков:
— это хорошие оптимизации; во всех проблемах виноваты пользователи.
Просто забудем про эти оптимизации?
Тесты производительности в ClickHouse
Тесты производительности в ClickHouse
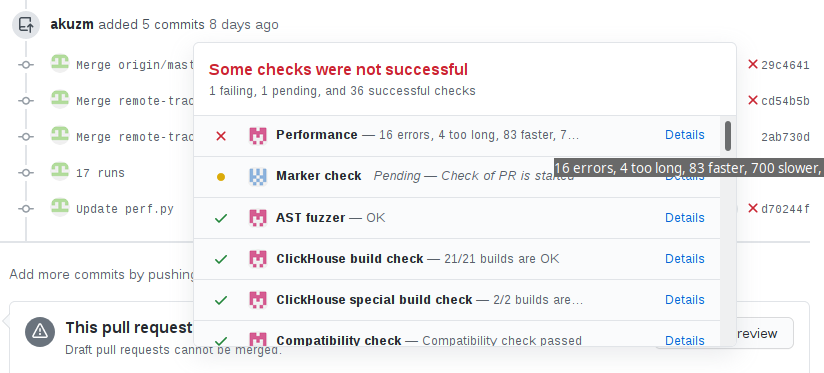
Тесты производительности в ClickHouse

Тесты производительности в ClickHouse
— выполняет запрос вперемешку на двух разных сборках сервера;
— собираем статистику времени выполнения:
например 10 запусков на старой версии и 10 на новой;
— берём bootstrap распределение случайной величины:
какова разница во времени выполнения запроса
на случайно выбранной паре запусков на старой и новой версии.
— считаем медиану этой случайной величины
и сравниваем с 95% квантилем случайной величины,
посчитанной если сравнивать сервер сам с собой.
Box, Hunter, Hunter "Statictics for exprerimenters", p. 78: "A Randomized Design Used in the Comparison of Standard and Modified Fertilizer Mixtures for Tomato Plants."
Тесты производительности в ClickHouse
Выдаёт один из результатов:
— разница несущественная;
— запрос ускорился;
— запрос замедлился;
— запрос нестабилен.
Иногда вместо нестабильного запроса
показывается ложное ускорение или замедление.
Почему время выполнения запроса может быть нестабильным?
Тесты производительности в ClickHouse
Почему время выполнения запроса может быть нестабильным?
Надо смотреть на метрики выполнения запроса:
— метрики userspace:
время выполнения запроса, rows processed, opened files;
— метрики ядра ОС:
время ожидания выполнения, iowait, blkio read bytes;
— метрики CPU:
instructions, branch mispredictions, L1d cache misses, dTLB misses;
Все эти метрики есть в ClickHouse и считаются на каждый запрос!
Тесты производительности в ClickHouse
Тесты производительности в ClickHouse
Проблема
Pull request с добавлением поддержки
типов UInt256, Int256, Decimal256.
Увеличился размер бинарника (324 МБ -> 429 МБ).
По perf тестам замедлений нет.
Но выросло количество нестабильных запросов!
Проблема
Выросло количество нестабильных запросов!
Перебором всех метрик выяснили, что:
— увеличилось количество iTLB misses.
Проблема
Увеличилось количество iTLB misses.
Кажется надо засунуть сегмент с кодом в Huge Pages :)
Как это сделать?
Использовать hugetlbfs? Но в тестовой инфраструктуре
не получится выделить явные huge pages.
И придётся как-то странно делать линковку.
Использовать transparent huge pages?
Но они работают только для anonymous memory mappings.
А наш код - это mmap сегмента исполняемого файла.
Безумное решение
Надо сделать remap машинного кода налету!
— выделить новый кусок памяти для кода (mmap);
— сделать madvise(..., MADV_HUGE);
— сделать mprotect, добавить executable и убрать write access;
— скопировать туда машинный код;
— передать ему управление.
Безумное решение
Надо сделать remap машинного кода налету!
Не работает, потому что у нас не Position Independent Code*.
* потому что так более оптимально, +1% производительности.
Надо удалить старый код, выделить на старом месте
новый кусок памяти и скопировать машинного код туда.
Худший код, который я писал в жизни.
Безумное решение
Шаг 1: определим адрес и длину куска памяти с нашим кодом.
std::pair<void *, size_t> getMappedArea(void * ptr)
{
uintptr_t uintptr = reinterpret_cast<uintptr_t>(ptr);
ReadBufferFromFile in("/proc/self/maps");
while (!in.eof())
{
uintptr_t begin = readAddressHex(in);
assertChar('-', in);
uintptr_t end = readAddressHex(in);
skipToNextLineOrEOF(in);
if (begin <= uintptr && uintptr < end)
return {reinterpret_cast<void *>(begin), end - begin};
}
throw Exception("Cannot find mapped area for pointer", ErrorCodes::LOGICAL_ERROR);
}
Безумное решение
Шаг 1: определим адрес и длину куска памяти с нашим кодом.
void remapExecutable()
{
auto [begin, size] = getMappedArea(
reinterpret_cast<void *>(remapExecutable));
remapToHugeStep1(begin, size);
}
Безумное решение
Шаг 1: определим адрес и длину куска памяти с нашим кодом.
void remapExecutable()
{
auto [begin, size] = getMappedArea(
reinterpret_cast<void *>(+[]{}));
// Don't write code like this.
remapToHugeStep1(begin, size);
}
* не пишите так.
Безумное решение
Шаг 2: выделим временный кусок памяти,
скопируем туда код и передадим ему управление.
void remapToHugeStep1(void * begin, size_t size)
{
/// Allocate scratch area and copy the code there.
void * scratch = mmap(nullptr, size,
PROT_READ | PROT_WRITE | PROT_EXEC, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (MAP_FAILED == scratch)
throwFromErrno(fmt::format("Cannot mmap {} bytes", size),
ErrorCodes::CANNOT_ALLOCATE_MEMORY);
memcpy(scratch, begin, size);
/// Offset to the scratch area from previous location.
int64_t offset = reinterpret_cast<intptr_t>(scratch) - reinterpret_cast<intptr_t>(begin);
/// Jump to the next function inside the scratch area.
reinterpret_cast<void(*)(void*, size_t, void*)>(
reinterpret_cast<intptr_t>(remapToHugeStep2) + offset)(begin, size, scratch);
}
Безумное решение
Шаг 3: удалим старый код и выделим новый кусок памяти на его месте.
void remapToHugeStep2(void * begin, size_t size, void * scratch)
{
int munmap_res = munmap(begin, size);
if (munmap_res == 0)
std::cerr << "Successfully unmapped\n";
/// ^ здесь segfault :(
Безумное решение
Шаг 3: удалим старый код и выделим новый кусок памяти на его месте.
После munmap кода, вызов любой функции приведёт к segfault,
так как функции в не-PIC коде вызываются по абсолютным адресам*, которых больше нет.
Но нам нужны функции mmap, madvise, mprotect, memcpy!
mmap, madvise, mprotect — обёртки над системными вызовами;
memcpy — полностью userspace функция.
* функции из .so, как libc.so, вызываются чуть по-другому.
Системные вызовы
std::cerr << "Hello, world\n";
— C++
write(2, "Hello, world\n", 13);
— Libc, POSIX
syscall(SYS_write, 2, "Hello, world\n", 13);
— Libc
__asm__("movq %rdi, %rax;
...
syscall")
Системные вызовы
__attribute__((__noinline__)) int64_t our_syscall(...)
{
__asm__ __volatile__ (R"(
movq %%rdi,%%rax;
movq %%rsi,%%rdi;
movq %%rdx,%%rsi;
movq %%rcx,%%rdx;
movq %%r8,%%r10;
movq %%r9,%%r8;
movq 8(%%rsp),%%r9;
syscall;
ret
)" : : : "memory");
return 0;
}
Безумное решение
Шаг 3: удалим старый код и выделим новый кусок памяти на его месте.
int64_t (*syscall_func)(...) = reinterpret_cast<int64_t (*)(...)>(
reinterpret_cast<intptr_t>(our_syscall) + offset);
int64_t munmap_res = syscall_func(SYS_munmap, begin, size);
if (munmap_res != 0)
return;
/// Map new anonymous memory region in place of the old region with code.
int64_t mmap_res = syscall_func(SYS_mmap, begin, size, ... MAP_FIXED, -1, 0);
if (-1 == mmap_res)
syscall_func(SYS_exit, 1);
/// As the memory region is anonymous, we can do madvise with MADV_HUGEPAGE.
syscall_func(SYS_madvise, begin, size, MADV_HUGEPAGE);
/// Copy the code from scratch area to the old memory location.
...
/// Make the memory area with the code executable and non-writable.
syscall_func(SYS_mprotect, begin, size, PROT_READ | PROT_EXEC);
void(* volatile step3)(void*, size_t, size_t) = remapToHugeStep3;
step3(scratch, size, offset);
Безумное решение
Шаг 4: удалим временный кусок памяти и вернёмся в точку вызова.
void remapToHugeStep3(void * scratch, size_t size, size_t offset)
{
/// The function should not use the stack,
/// otherwise various optimizations, including "omit-frame-pointer" may break the code.
/// Unmap the scratch area.
our_syscall(SYS_munmap, scratch, size);
/// The return address of this function is pointing to the scratch area
/// (because it was called from there).
/// But the scratch area no longer exists.
/// We should correct the return address by subtracting the offset.
__asm__ __volatile__("subq %0, 8(%%rsp)" : : "r"(offset) : "memory");
}
Безумное решение
Оно работает.
Не работает в debug сборке.
Не работает с sanitizers.
Есть ли польза?
Можно ли включать в продакшене?
А что мы всё-таки сделали?
Очень хитрым способом поменяли сегмент с кодом в памяти
— для того, чтобы он стал использовать Huge Pages
— в надежде уменьшить количество iTLB промахов
— чтобы уменьшить ложные срабатывания perf-тестов в CI.
Результат:
1. Всё работает, Huge Pages действительно используются.
2. Количество iTLB промахов уменьшилось почти до нуля!
3. Скорость работы запросов никак не изменилась :(
4. Увеличилась ли стабильность perf-тестов? — пока неизвестно.
Выводы
Хотите что-то оптимизировать — сначала научитесь измерять.
Готовьтесь проводить много экспериментов,
большинство из которых не оправдаются.
Надёжные тесты производительности сделать сложно.
Несмотря на наличие измерений и continuous integration,
последствия оптимизаций могут стать известны только в продакшене.
Самые рискованные оптимизации — под конкретное железо
и особенности его работы.